Trusted Worldwide Questions & Answers
Most Recent IBM C1000-130 Exam Dumps
Prepare for the IBM Cloud Pak for Integration V2021.2 Administration exam with our extensive collection of questions and answers. These practice Q&A are updated according to the latest syllabus, providing you with the tools needed to review and test your knowledge.
QA4Exam focus on the latest syllabus and exam objectives, our practice Q&A are designed to help you identify key topics and solidify your understanding. By focusing on the core curriculum, These Questions & Answers helps you cover all the essential topics, ensuring you're well-prepared for every section of the exam. Each question comes with a detailed explanation, offering valuable insights and helping you to learn from your mistakes. Whether you're looking to assess your progress or dive deeper into complex topics, our updated Q&A will provide the support you need to confidently approach the IBM C1000-130 exam and achieve success.
The questions for C1000-130 were last updated on Mar 28, 2025.
- Viewing page 1 out of 23 pages.
- Viewing questions 1-5 out of 113 questions
An administrator is looking to install Cloud Pak for Integration on an OpenShift cluster. What is the result of executing the following?
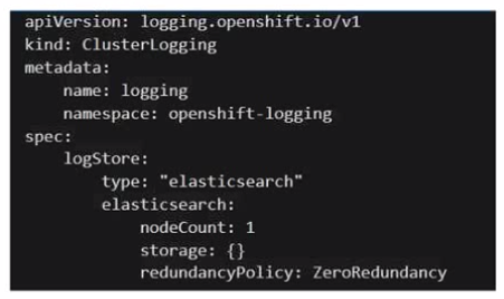
The given YAML configuration is for ClusterLogging in an OpenShift environment, which is used for centralized logging. The key part of the specification that determines the behavior of Elasticsearch is:
logStore:
type: 'elasticsearch'
elasticsearch:
nodeCount: 1
storage: {}
redundancyPolicy: ZeroRedundancy
Analysis of Key Fields:
nodeCount: 1
This means the Elasticsearch cluster will consist of only one node (single-node deployment).
storage: {}
The empty storage field implies no persistent storage is configured.
This means that if the pod is deleted or restarted, all stored logs will be lost.
redundancyPolicy: ZeroRedundancy
ZeroRedundancy means there is no data replication, making the system vulnerable to data loss if the pod crashes.
In contrast, a redundancy policy like MultiRedundancy ensures high availability by replicating data across multiple nodes, but that is not the case here.
Evaluating Answer Choices:
Option
Explanation
Correct?
A . A single node ElasticSearch cluster with default persistent storage.
Incorrect, because storage: {} means no persistent storage is configured.
B . A single infrastructure node with persisted ElasticSearch.
Incorrect, as this is not configuring an infrastructure node, and storage is not persistent.
C . A single node ElasticSearch cluster which auto scales when redundancyPolicy is set to MultiRedundancy.
Incorrect, because setting MultiRedundancy does not automatically enable auto-scaling. Scaling needs manual intervention or Horizontal Pod Autoscaler (HPA).
D . A single node ElasticSearch cluster with no persistent storage.
Correct, because nodeCount: 1 creates a single node, and storage: {} ensures no persistent storage.
Final Answer:
D. A single node ElasticSearch cluster with no persistent storage.
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration Reference:
IBM CP4I Logging and Monitoring Documentation
Red Hat OpenShift Logging Documentation
Elasticsearch Redundancy Policies in OpenShift Logging
What role is required to install OpenShift GitOps?
In Red Hat OpenShift, installing OpenShift GitOps (based on ArgoCD) requires elevated cluster-wide permissions because the installation process:
Deploys Custom Resource Definitions (CRDs).
Creates Operators and associated resources.
Modifies cluster-scoped components like role-based access control (RBAC) policies.
Only a user with cluster-admin privileges can perform these actions, making cluster-admin the correct role for installing OpenShift GitOps.
Command to Install OpenShift GitOps:
oc apply -f openshift-gitops-subscription.yaml
This operation requires cluster-wide permissions, which only the cluster-admin role provides.
Why the Other Options Are Incorrect?
Option
Explanation
Correct?
A . cluster-operator
Incorrect -- No such default role exists in OpenShift. Operators are managed within namespaces but cannot install GitOps at the cluster level.
C . admin
Incorrect -- The admin role provides namespace-level permissions, but GitOps requires cluster-wide access to install Operators and CRDs.
D . operator
Incorrect -- This is not a valid OpenShift role. Operators are software components managed by OpenShift, but an operator role does not exist for installation purposes.
Final Answer:
B. cluster-admin
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration Reference:
Red Hat OpenShift GitOps Installation Guide
Red Hat OpenShift RBAC Roles and Permissions
IBM Cloud Pak for Integration - OpenShift GitOps Best Practices
Which option should an administrator choose if they need to run Cloud Pak for Integration (CP4I) on AWS but do not want to have to manage the OpenShift layer themselves?
When deploying IBM Cloud Pak for Integration (CP4I) v2021.2 on AWS, an administrator has multiple options for managing the OpenShift layer. However, if the goal is to avoid managing OpenShift manually, the best approach is to deploy CP4I onto AWS ROSA (Red Hat OpenShift Service on AWS).
Why is AWS ROSA the Best Choice?
Managed OpenShift: ROSA is a fully managed OpenShift service, meaning AWS and Red Hat handle the deployment, updates, patching, and infrastructure maintenance of OpenShift.
Simplified Deployment: Administrators can directly deploy CP4I on ROSA without worrying about installing and maintaining OpenShift on AWS manually.
IBM Support: IBM Cloud Pak solutions, including CP4I, are certified to run on ROSA, ensuring compatibility and optimized performance.
Integration with AWS Services: ROSA allows seamless integration with AWS-native services like S3, RDS, and IAM for authentication and storage.
Why Not the Other Options?
B . Installer-provisioned Infrastructure on EC2 -- This requires manual setup of OpenShift on AWS EC2 instances, increasing operational overhead.
C . CP4I Quick Start on AWS -- IBM provides a Quick Start guide for deploying CP4I, but it assumes you are managing OpenShift yourself. This does not eliminate OpenShift management.
D . Terraform scripts from IBM's GitHub -- These scripts help automate provisioning but still require the administrator to manage OpenShift themselves.
Thus, for a fully managed OpenShift solution on AWS, AWS ROSA is the best option.
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration Reference:
IBM Cloud Pak for Integration Documentation
IBM Cloud Pak for Integration on AWS ROSA
Deploying Cloud Pak for Integration on AWS
Red Hat OpenShift Service on AWS (ROSA) Overview
Which queue manager includes a pair of pods, one of which is the active queue manager and the other of which is a standby?
In IBM Cloud Pak for Integration (CP4I) v2021.2, IBM MQ provides multiple high-availability (HA) deployment options. A multi-instance queue manager consists of a pair of pods:
One active queue manager (handling message processing).
One standby queue manager (ready to take over if the active instance fails).
The standby instance continuously monitors the active queue manager, and if it detects a failure, it automatically takes over, ensuring minimal downtime and high availability.
Why the other options are incorrect:
A . Native HA -- Incorrect
Native HA (Highly Available) queue managers use persistent storage and multiple replicas for redundancy but do not rely on an active-standby pod setup. Instead, they use Raft consensus for leader election and failover.
They are different from multi-instance queue managers, which explicitly have one active and one standby pod.
C . Single Resilient -- Incorrect
A Single Resilient queue manager has only one instance running and recovers using persistent storage, but it does not have a standby pod for immediate failover.
D . Replicated Data -- Incorrect
'Replicated Data' is not a specific IBM MQ HA mode. Instead, Native HA queue managers use replicated data across multiple pods to ensure resilience.
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration Reference:
IBM MQ Multi-Instance Queue Manager Documentation
IBM Cloud Pak for Integration -- High Availability Configurations
OpenShift Deployment of IBM MQ
Which statement is true about App Connect Designer?
In IBM Cloud Pak for Integration (CP4I) v2021.2, App Connect Designer is a low-code integration tool that enables users to design and deploy integrations between applications and services. It runs as a containerized service within OpenShift.
Why Option C is Correct:
OpenShift supports multi-instance deployments, allowing users to create multiple instances of App Connect Designer within the same namespace.
This flexibility enables organizations to run separate designer instances for different projects, teams, or environments within the same namespace.
Each instance operates independently, and users can configure them with different settings and access controls.
Explanation of Incorrect Answers:
Unlock All Questions for IBM C1000-130 Exam
Full Exam Access, Actual Exam Questions, Validated Answers, Anytime Anywhere, No Download Limits, No Practice Limits
Get All 113 Questions & Answers