Trusted Worldwide Questions & Answers
Most Recent Microsoft DP-500 Exam Questions & Answers
Prepare for the Microsoft Designing and Implementing Enterprise-Scale Analytics Solutions Using Microsoft Azure and Microsoft Power BI exam with our extensive collection of questions and answers. These practice Q&A are updated according to the latest syllabus, providing you with the tools needed to review and test your knowledge.
QA4Exam focus on the latest syllabus and exam objectives, our practice Q&A are designed to help you identify key topics and solidify your understanding. By focusing on the core curriculum, These Questions & Answers helps you cover all the essential topics, ensuring you're well-prepared for every section of the exam. Each question comes with a detailed explanation, offering valuable insights and helping you to learn from your mistakes. Whether you're looking to assess your progress or dive deeper into complex topics, our updated Q&A will provide the support you need to confidently approach the Microsoft DP-500 exam and achieve success.
The questions for DP-500 were last updated on Jan 20, 2025.
- Viewing page 1 out of 32 pages.
- Viewing questions 1-5 out of 162 questions
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are using an Azure Synapse Analytics serverless SQL pool to query a collection of Apache Parquet files by using automatic schema inference. The files contain more than 40 million rows of UTF-8-encoded business names, survey names, and participant counts. The database is configured to use the default collation.
The queries use open row set and infer the schema shown in the following table.

You need to recommend changes to the queries to reduce I/O reads and tempdb usage.
Solution: You recommend defining a data source and view for the Parquet files. You recommend updating the query to use the view.
Does this meet the goal?
Solution: You recommend using OPENROWSET WITH to explicitly specify the maximum length for businessName and surveyName.
The size of the varchar(8000) columns are too big. Better reduce their size.
A SELECT...FROM OPENROWSET(BULK...) statement queries the data in a file directly, without importing the data into a table. SELECT...FROM OPENROWSET(BULK...) statements can also list bulk-column aliases by using a format file to specify column names, and also data types.
You have a Power Bl workspace named workspace1 that contains three reports and two dataflows.
You have an Azure Data Lake Storage account named storage1.
You need to integrate workspace1 and storage1.
What should you do first?
You need to optimize the workflow for the creation of reports and the adjustment of tables by the enterprise analytics team.
What should you do?
You need to provide users with a reproducible method to connect to a data source and transform the data by using an Al function. The solution must meet the following requirement
* Minimize development effort.
* Avoid including data in the file.
Which type of file should you create?
A PBIT file is a template created by Power BI Desktop, a Microsoft application used to create reports and visualizations. It contains queries, visualization settings, data models, reports, and other data added by the user.
A PBIT file acts as a Power BI template. It doesn't include any data from your source systems.
You have the following Python code in an Apache Spark notebook.
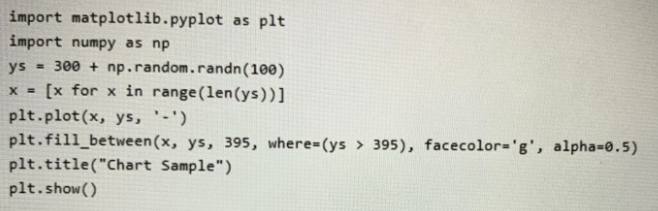
Which type of chart will the code produce?
The matplotlib.pyplot.fill_between function fills the area between two horizontal curves.
The curves are defined by the points (x, y1) and (x, y2). This creates one or multiple polygons describing the filled area.
Unlock All Questions for Microsoft DP-500 Exam
Full Exam Access, Actual Exam Questions, Validated Answers, Anytime Anywhere, No Download Limits, No Practice Limits
Get All 162 Questions & Answers